

DeepSpeech by Baidu Inc.
DeepSpeech came all the way in 2014 from Baidu Inc. published by my senior friend Awni Hannun and et. al. who came from YCombinator and graduated from Standford University, San Franscio. He is currently working at Facebook AI Research (FAIR).
After the release of DeepSpeech or DeepSpeech 1, the next year DeepSpeech 2 was released (2015). DeepSpeech takes an audio feature as an input and output the audio transcript. Today’s discussion is based on DeepSpeech 2, however there is Deepspeech 3 and other state-of-the art for ASR.
The network consist of five layer, the input features are fed into three fully connected layers, followed by a bidirectional LSTM layer, and lastly to the fully connected layer. The hidden layer at the fully connected layers uses the ReLU activation. The LSTM uses tanh activation.
The output from this layer will be the matrix of probabilities over time. At each time step of 20 mili seconds, the network yields and output of each characters from the alphabet, which is the likelihood of the character being said in the audio. CTC loss function allow us maximize the likelihood of the probability of the character be correct.
Since the paper do not mention anything about the hyperparameters so implementing is tedious to get the result based on the paper. Hence, we refer to the open source implementation of the DeepSpeech by Mozilla.
Thanks to Mozilla for making it open source and providing it in GitHub.
Training on DeepSpeech
Mozilla’s implementation of DeepSpeech is based on tensorflow.
Preparing the csv file of data
The input data for the Acoustic model are the “train.csv”, “test.csv” and “dev.csv” files The csv file is in the format of: wav_filepath, wav_filesize, transcript
Eg:
wav_filepath, wav_filesize, transcript
/path/to/wavefile/file1.wav, 205xxx, this is a sample sentence
/path/to/wavefile/file2.wav, 781xx, the dog ate the sweets
Preparing the alphabets
For training the english ASR model, the alphabets consist of 26 english alphabets (a-z)
and 0-9 (10) digit integers.
For Chinese Model, requires the pinyin alphabets along with 10 digits from 0 to 9.
Language Model
We shall prepare our language mode using KenLM.
The Mozilla DeepSpeech recommend us to use KenLM which is most compatible lm for the training.
First we need a corpus of vocabulary to create language model.
Install the KenLM tool
wget -O - https://kheafield.com/code/kenlm.tar.gz |tar xz
mkdir kenlm/build
cd kenlm/build
cmake ..
make -j2
once you build the KenLM tool, its time to create a language model from the vocabulary corpus.
bin/lmplz -o 5 vocabulary.txt text.arpa
This will generate intermediate product with arpa extension.
Now, let’s run one script
bin/build_binary text.arpa text.binary
So, we have the language model (lm) named text.binary
Trie model
Building a trie model is pretty simple and straightforward. Trie model is used during the decoding process after ctc,
the task i mentioned earlier. It dose the beam search for every character output from the acoustic model.
we can generate the trie model from the native_client provided by the deepspeech.
native_client/generate_trie language_model.binary, alphabets.txt, vocabulary trie.binary
Training the ASR model
By now we have everything, except the last missing piece of puzzle and obvious i.e asr model.
Let’s train with the deepspeech
$ python DeepSpeech.py --train_files /data/zh_data/data_thchs30/mini_train.csv --dev_files /data/zh_data/data_thchs30/mini_dev.csv --test_files /data/zh_data/data_thchs30/mini_test.csv --alphabet_config_path /data/zh_data/alphabet.txt --lm_binary_path /data/zh_data/zh_lm.binary --lm_trie_path /data/zh_data/trie --decoder_library_path native_client/libctc_decoder_with_kenlm.so --checkpoint_dir /data/zh_data/checkpoint/ --validation_step --epochs 75
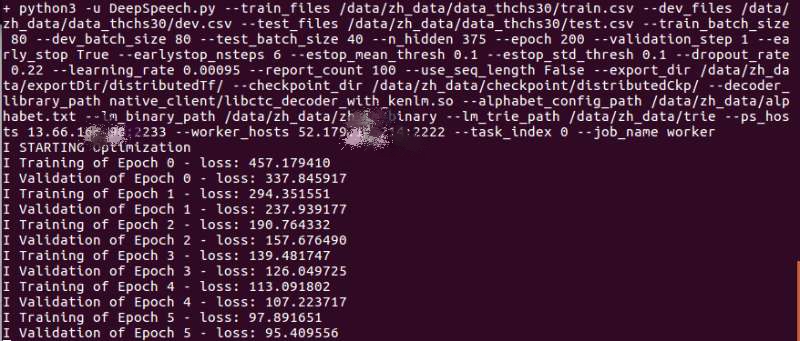
Since I use distributed tensorflow, as described in my youTube video,
the process looks lik this in parameter server.

and Worker server looks like this
Once, the training is almost over, the evaluation will be show as
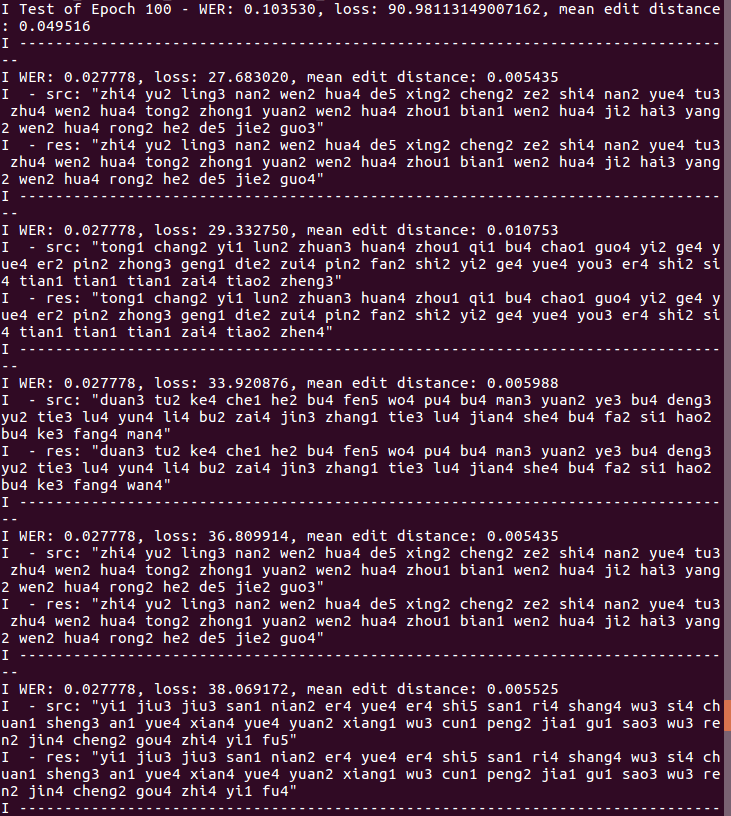
The above training uses distributed tensorflow. I also used horovod implementation for training using MPI.